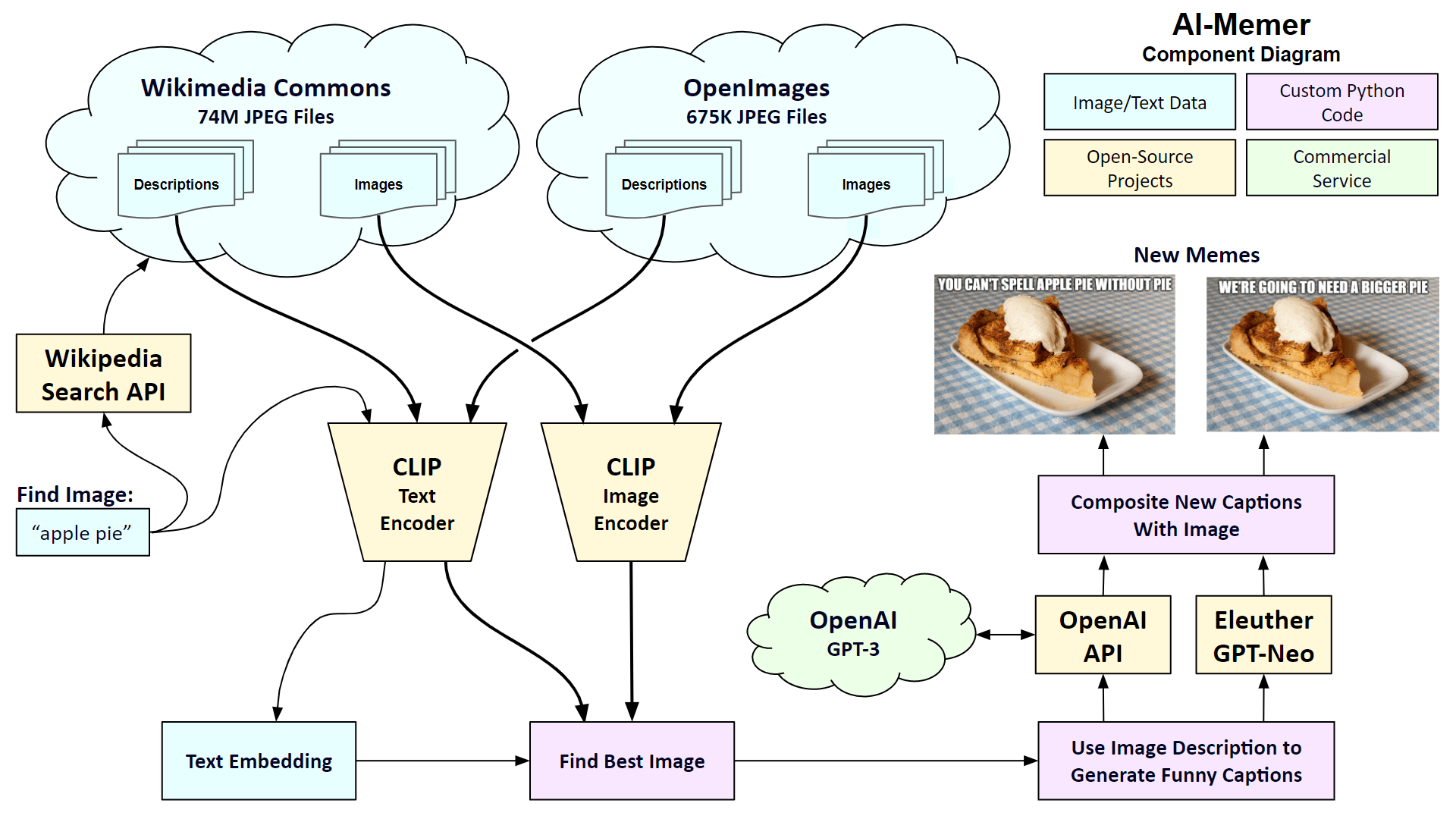
The user starts by entering a search query to find a background image, like “apple pie”. The system then checks for matching images in Wikimedia Commons and the OpenImages dataset. Both datasets have corresponding text descriptions of the images. I use the CLIP encoders from OpenAI to first perform a semantic search on the text descriptions. A semantic search looks for matching concepts, not just a word search. I then perform a semantic search on the images. The user checks out the top 10 images that match the query and selects their favorite. Either the GPT-3 model from OpenAI or the GPT-Neo model from EleutherAI is used to generate 10 possible captions. The user selects the best caption to create the new meme, which can be downloaded.
What are memes, again?
The Wiktionary defines the word meme as “any unit of cultural information, such as a practice or idea, that is transmitted verbally or by repeated action from one mind to another in a comparable way to the transmission of genes.” The term originated in Richard Dawkins’ book, The Selfish Gene. In the age of the Internet, the term meme has been narrowed to mean a piece of content, typically an image with a funny caption, that’s spread online via social media.
Here’s what others created before me
Dylan Wenzlau created an automatic meme generator using a deep convolutional network. He used 100M public meme captions by users of the Imgflip Meme Generator and trained the system to generate captions based on 48 commonly used background images. You can read about his system here, and run it online here. Here are three examples: These are pretty good but the system is limited to use only common background images. I was looking for a way to inject a set of new images into the memesphere.
Meet AI-Memer
The AI-Memer system creates memes in three steps: finding background images, generating captions, and typesetting the meme captions.
Source code and acknowledgments
All source code for this project is available on GitHub. You can experiment with the code using this Google Colab. I released the source code under the CC BY-SA license.
Wikimedia Commons
The Wikimedia Commons has over 73 million JPEG files. Most of them are released with permissive rights, like the Creative Commons Attribution license. I use Goldsmith’s Wikipedia search API to find the top 3 pages related to the text query and gather the image descriptions using the CommonsAPI on the Magnus Toolserver. I use the shutil.copyfileobj() function in Python to download the image files. There are typically 3 to 10 images on a Wikipedia page so there will be about 9 to 30 images in total coming down.
OpenImages
The OpenImages dataset from Google is comprised of 675,000 photos scraped from Flikr that were all released under the Creative Commons Attribution license. A dataset of image descriptions is available for download. I ran each of the descriptions through OpenAI’s CLIP system and cached the embeddings for quick access. When the user types in a query, I run it through CLIP and compare it to the cached embeddings. I then download the top 20 matching images using the OpenImages download API. For a final filtering pass, I run the images from the 3 Wikipedia pages and the 20 images from the OpenImages through the image encoder and compare the results to the embedding of the text query. I present the top 10 images to the user to choose their favorite. For example, if you search for “apple pie”, you will be presented with the top 10 images sorted by closest match.
GPT-3 Da Vinci
OpenAI’s GPT-3 Da Vinci is currently the largest AI model for Natural Language Processing. I am using their latest “zero-shot” style of prompting with their new Da Vinci Instruct model. Instead of providing examples of what you are asking the model to do, you can just simply ask it what to do directly. Here is the prompt that creates a caption for the apple pie picture. I pass the prompt into the call to OpenAI along with some additional parameters. Here’s the Python code. The max_token parameter indicates how long the response should be. The temperature and top_p parameters are similar in that they indicate the amount of variety in the response. The frequency_penalty and presence_penalty are also similar in that they control how often there are new deviations and new topics in the response. If you want to know what all these parameters do, check out my article from last month, here. Before I show examples of the output from GPT-3, here is the legal disclaimer that OpenAI suggests that I show, which is all true. The author generated the following text in part with GPT-3, OpenAI’s large-scale language-generation model. Upon generating draft language, the author reviewed and revised the language to their own liking and takes ultimate responsibility for the content of this publication. Running the code 10 times will yield the following results, at a total cost of $0.03. Note that I formatted the text to be in uppercase. OK, these are pretty good. One thing I learned is that GTP-3 Da Vinci can be funny! For example, caption number 2 seems to refer to the “easy as pie” idiom. Note that GPT-3, like all AI models trained on a large corpus of text, will reflect societal biases. Occasionally the system will produce text that may be inappropriate or offensive. OpenAI has a feature to label generated text with one of three warning levels: 0 – the text is safe, 1 – this text is sensitive, or 2 – this text is unsafe. My code will show a warning for any of the generated captions that are flagged as sensitive or unsafe.
GPT-Neo
GPT-Neo is a transformer model created primarily by developers known as sdtblck and leogao2 on GitHub. The project is an implementation of “GPT-2 and GPT-3-style models using the mesh-tensorflow library.” So far, their system is the size of OpenAI’s GPT-3 Ada, their smallest model. But GPT-Neo is available for free. I used the Huggingface Transformers interface to access GPT-Neo from my Python code. Since GPT-Neo doesn’t have “instruct” versions of their pre-trained models, I had to write a “few-shot” prompt in order to get the system to generate captions for memes using examples. Here’s the prompt I wrote using Disaster Girl and Grumpy Cat memes with example captions. After setting the temperature parameter to 0.7 and the top_p to 1.0, I pass the prompt into GPT-Neo to generate new captions. Here’s the code to generate a caption. Theme: disaster girl Image description: A picture of a girl looking at us as her house burns down Caption: There was a spider. It’s gone now. Theme: grumpy cat Image description: A face of a cat who looks unhappy Caption: I don’t like Mondays. Theme: apple pie. Image description: Simple and easy apple pie served with vanilla ice cream, on a gingham tablecloth in Lysekil, Sweden. Caption: Here are the sample results. Hmmm. These are not as good as the GPT-3 captions. Most of them are quite simple and not very funny. Number 10 is just plain absurd. But number 4 seems to be OK. Let’s use this as our caption. The final step is to compose the meme by writing the caption into the background image.
Typesetting memes
Adding the captions to memes is fairly straightforward. Most memes are composed using the Impact font designed by Geoffrey Lee in 1965. For AI-Memer, I used some code by Emmanuel Pire for positioning and rendering the caption into the background image. I give the user the option to adjust the size of the font and place the caption at the top or bottom of the image. Here are our two memes. The caption on the left was generated by GPT-3 and the one on the right was generated by GPT-Neo.
Discussion
With this project, I learned that large-scale language-generation models can create good captions for memes given a description of the image. Although many of the generated captions are straightforward, occasionally they can be very clever and funny. The GPT-3 Da Vinci model, in particular, seems to create clever memes frequently, demonstrating both a command of the language with a seemingly deep understanding of cultural history.
Next steps
Although the results are pretty good, there is definitely room for improvement. For example, the choices for background images seem somewhat limited, especially for pop culture. This may be due to the fact that I am restricting the search to use only freely licensed photos. I don’t know if a US court has weighed in yet on whether or not the background images in memes can be deemed to be fair use or not, so I’ll leave that question to the lawyers. The developers behind GPT-Neo at EleutherAI are continuing to build and train bigger language models. Their next model is called GPT-NeoX. They say their “primary goal is to train an equivalent model to the full-sized GPT-3 and make it available to the public under an open license.” If you create any memes with AI-Memer and post them online, please mention the project and add a link to this article. I would like to thank Jennifer Lim and Oliver Strimpel for their help with this project. This article by Robert A. Gonsalves was originally published by Towards Data Science. Robert is an artist, inventor, and engineer in the Boston area. Don’t forget to check out more of his generated memes in the appendix here.